문제를 읽고 그냥 정렬하면 되네~하면 안되는 문제이다. 처음 입력 받은 순서대로 답을 출력해주어야한다.
에이~ 그러면 그냥 똑같은 배열 두개 만들어서, 하나는 냅두고 다른 하나는 정렬해서 답 내면 되잖아 ㅋㅋ
그런 분들에게 말한다. 이 문제의 핵심은 "나보다 작은 수가 몇개냐?" 이다. 근데 이제 여기에 서로 다른 수가 추가된..
자, 밑에 그림과 같이 똑같은 배열 두개가 있고 하나는 정렬되어있는 상태라고 생각해보자.

입력받은 배열을 기준으로 답을 찾아 출력해보자.
- 2 보다 작은 서로 다른 수의 개수 = 2
- 4 보다 작은 서로 다른 수의 개수 = 3
- -10 보다 작은 서로 다른 수의 개수 = 0
- 4 보다 작은 서로 다른 수의 개수 = 3
- -9 보다 작은 서로 다른 수의 개수 = 1
- 6 보다 작은 서로 다른 수의 개수 = 4
혹시 어떻게 \(x\)보다 작은 서로 다른 수의 개수를 세었는가 ? 정렬한 배열에서 하나씩 세셨다면..
어이고... 그러면 최악의 경우에 정렬한 배열을 처음부터 끝까지 다 봐야하는 경우(=\(O(n)\))가 생긴다.
따라서 시간복잡도가 \(O(n * n) = O(n^2)\)이 되기 때문에 시간초과될 확률이 너무나도 높다.
시간복잡도를 줄여보자. 입력받은 배열에서 한번 쭉~ 도는 것을 줄일 순 없다.
그렇다면, 답을 찾는 시간복잡도를 \(O(n)\)에서 \(O(log n)\) 또는 \(O(1)\)으로 줄여보자.
정해라고 생각되는 \(O(1)\)부터 보자.
정렬할 배열의 구성을 좀 바꿔주자. 입력받은 수만 저장하지말고 ( 입력받은 수, index ) 같이 저장하자.
그러면 이렇게 된다.

이제부터 입력받은 배열을 답을 저장한 배열로 바꿔줄 것이다. 어떻게 ???
자, 서로 다른 수의 개수를 저장할 변수(count) 하나를 갖고 정렬한 배열을 처음부터 끝까지 쭈우욱 돌아보자.
첫번째 칸은 당연히 자신보다 작은 서로 다른 수가 없기 때문에, 바로 첫번째 칸에 들어있는 index에 접근하여 현재 서로 다른 수의 개수를 넣어주자.
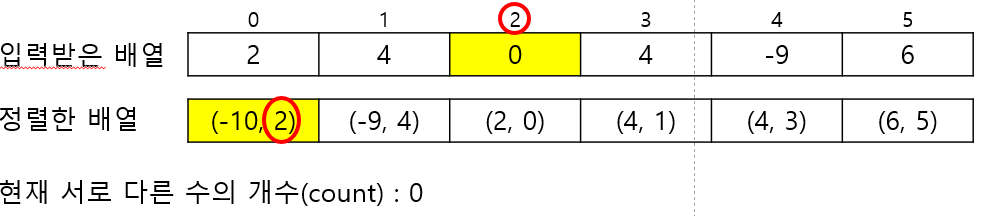
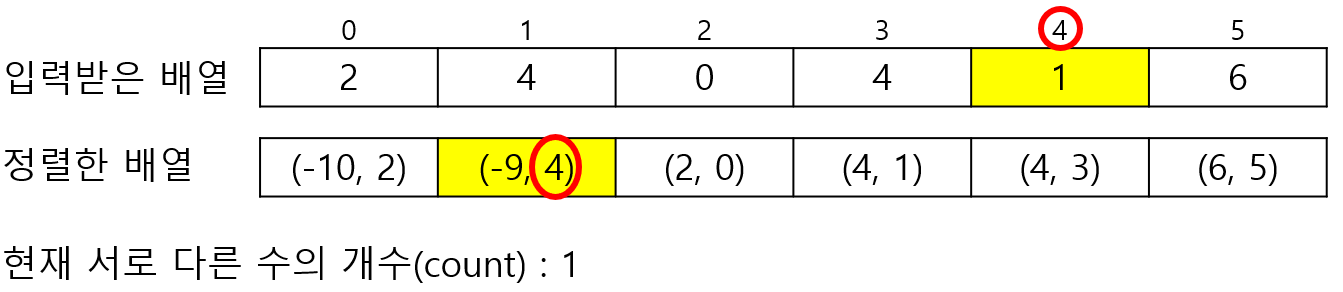
두번째 칸을 보자.가장 먼저 해줄 일은 이전 칸에 저장된 값과 지금 보고 있는 칸에 저장된 값이 다른지? 이다.
만약 다르다면, 나보다 작은 서로 다른 수의 개수가 하나 더 많아져야한다.
확인이 끝난 후 저장된 인덱스에 접근하여 현재 서로 다른 수의 개수를 저장해주면 된다.
이제 계속 똑같이 진행해주면 된다.

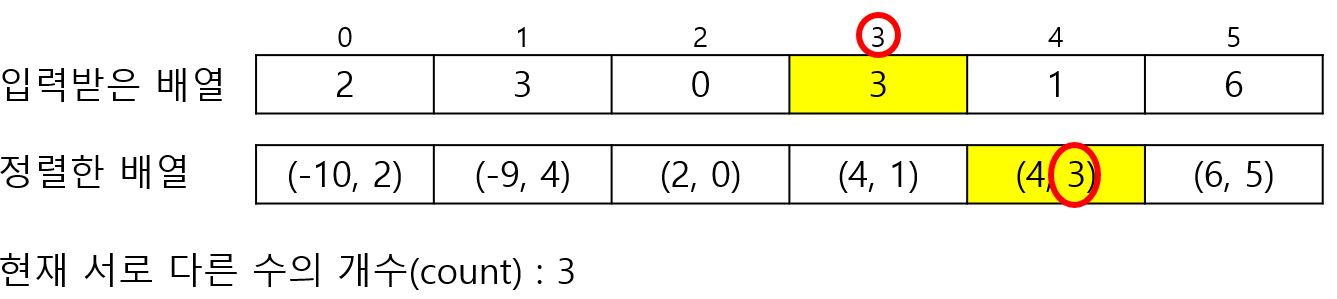

모든 과정이 끝나고 입력받은 배열만 출력해주면 된다.
#include <bits/stdc++.h>
using namespace std;
struct Pair {
int number;
int index;
bool operator< (const Pair& p) {
return this->number < p.number;
}
};
int num[1000001]; // 입력받는 배열
Pair ordered[1000001]; // 정렬할 배열
int main() {
ios::ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
int n;
cin >> n;
for (int i = 0; i < n; ++i) {
cin >> num[i];
ordered[i] = { num[i], i };
}
// 정렬
sort(ordered, ordered + n);
int cnt = 0;
num[ordered[0].index] = cnt; // 첫번째 칸 채우기
for (int i = 1; i < n; ++i) {
if (ordered[i].number != ordered[i - 1].number) ++cnt; // 이전 칸과 다른 값인지 ?
num[ordered[i].index] = cnt; // 저장된 인덱스에 접근해서 서로 다른 수의 개수 저장
}
for (int i = 0; i < n; ++i) cout << num[i] << ' ';
return 0;
}
이미 \(O(1)\)에 답을 찾는 방법을 설명했기 때문에, 이 밑에 부분은 그냥 궁금한 분들만 보시면 될 것 같다.
\(O(log n)\)방법은 간단하다. 정렬한 배열에서 중복수를 제거하고 이분탐색으로 답을 낼 수 있다.
근데 중복수를 제거할 때,
(중복수인지 확인 = \(O(n)\)) * (제거하는 시간 = \(O(n)\) \(=\) \(O(n^2)\)이라서 시간복잡도가 안줄지 않냐 ? 예리하다.
그래서 세 가지 방법이 있다.
- \(O(n logn)\)에 중복수 제거 => 배열 정렬 후에 중복되지 않은 수만 다른 vector에 추가
- \(O(n)\)에 중복수 제거 => C++의 unique함수
- \(O(logn)\)에 중복수 제거 => map 또는 set 컨테이너 사용
이분 탐색은 STL의 lower_bound를 이용하여 내가 원하는 수가 몇번 인덱스에 있는지 확인하면, 그 인덱스가 답이 된다.지적 유희 시간이기 때문에, unique와 lower_bound에 대해선 나중에 설명해보겠다.
1. \(O(n logn)\)에 중복수 제거
#include <bits/stdc++.h>
using namespace std;
int num[1000001];
int ordered[1000001];
vector<int> vec;
int main() {
ios::ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
int n;
cin >> n;
for (int i = 0; i < n; ++i) {
cin >> num[i];
ordered[i] = num[i];
}
// 정렬
sort(ordered, ordered + n);
vec.push_back(ordered[0]);
// 중복되지 않은 수들만 vec에 추가
for (int i = 1; i < n; ++i) if (ordered[i] != ordered[i - 1]) vec.push_back(ordered[i]);
for (int i = 0; i < n; ++i) cout << (int)(lower_bound(vec.begin(), vec.end(), num[i]) - vec.begin()) << ' ';
return 0;
}
2.\(O(n)\)에 중복수 제거
#include <bits/stdc++.h>
using namespace std;
int num[1000001];
vector<int> ordered;
int main() {
ios::ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
int n;
cin >> n;
ordered.resize(n);
for (int i = 0; i < n; ++i) {
cin >> num[i];
ordered[i] = num[i];
}
// 정렬
sort(ordered.begin(), ordered.end());
// unique를 이용해 중복 값을 모두 제거
ordered.resize(unique(ordered.begin(), ordered.end()) - ordered.begin());
for (int i = 0; i < n; ++i) cout << (int) (lower_bound(ordered.begin(), ordered.end(), num[i]) - ordered.begin()) << ' ';
return 0;
}
3 - 1. \(O(logn)\)에 중복수 제거 (map container)
#include <bits/stdc++.h>
using namespace std;
int num[1000001];
map<int, int> mp;
int main() {
ios::ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
int n;
cin >> n;
for (int i = 0; i < n; ++i) {
cin >> num[i];
mp[num[i]]++;
}
int cnt = 0;
for (auto it = mp.begin(); it != mp.end(); ++it) {
it->second = cnt++;
}
for (int i = 0; i < n; ++i) cout << mp[num[i]] << ' ';
return 0;
}
3 - 2. \(O(logn)\)에 중복수 제거 (set container로 중복 제거 후, map에 답을 저장)
#include <bits/stdc++.h>
#include <unordered_map>
using namespace std;
int num[1000001];
unordered_map<int, int> mp;
set<int> s;
int main() {
ios::ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
int n;
cin >> n;
for (int i = 0; i < n; ++i) {
cin >> num[i];
s.insert(num[i]);
}
int sum = 0;
for (auto it = s.begin(); it != s.end(); ++it) {
mp[*it] = sum++;
}
for (int i = 0; i < n; ++i) cout << mp[num[i]] << ' ';
return 0;
}
고생의 흔적들
'BOJ_단계별로 풀어보기(9단계~) > [11단계] 정렬' 카테고리의 다른 글
| [백준 10814] 나이순 정렬 (0) | 2022.03.09 |
|---|---|
| [백준 1181] 단어 정렬 (0) | 2022.03.09 |
| [백준 11651] 좌표 정렬하기 2 (0) | 2022.03.09 |
| [백준 11650] 좌표 정렬하기 (0) | 2022.03.09 |
| [백준 1427] 소트인사이드 (0) | 2022.03.08 |